端口和适配器架构——DDD好帮手

摘要
- 本文源自2018领域驱动设计中国峰会《领域驱动设计与演进式架构专题》的Session之一,是其博客版
- 在实践领域驱动设计时,可以挑选一些方法互为参照,端口和适配器架构概念简单,容易掌握,适合作为实践领域驱动设计的辅助方法。
大概一个月前,在做2018年领域驱动设计大会预告的时候,上一届大会的主题演讲者肖然提出这样的担忧:工具和方法似乎没有很好地解决“落地难”的挑战
- 没有一套方法能够打遍天下,具体到采用哪一种方案,仿佛都需要增加一个定语“这取决于……”。
- 不管是在DDD原著,还是后续不少专家的书籍中,都暗示、甚至明示架构设计的终极大招还是By Experience ——靠经验吃饭。
- 从战略角度的子领域划分,到战术建模层面实体、值对象的选择,最终的决策很可能不是完全“理性”的,经验这个“感性”的东西发挥着很大的作用” 所以,推动领域驱动设计实践的方向是否应该从介绍方法转变为介绍如何累积经验?
看了这篇文章后,我放弃了之前准备的话题《CQRS和Event Sourcing,从入门到放弃》,因为可能你一年都不会遇到一个需要使用这两种方法才能解决的复杂项目。
如何快速获取经验?无非就是多练,但是练了要讨论和总结,我遇到过这样的对话,我将它称为”两小儿辩DDD“: A: 我觉得你这里不该使用实体,应该使用值对象 B: 我觉得你这个接口不是领域服务,它其实是应用服务,你这样做不DDD A: 你的实体不应该调用Repository,你这样做也不DDD B: (看着我)你来评评理,我们谁说的对 我:俺也不知道,这取决于…
这样的复盘方式效果欠佳,我建议不妨从DDD中跳出,找一种方法互为参照和检验,比如”端口和适配器架构“
什么是端口和适配器架构
套用流行的提问方式:当我们在说架构时,我们在说什么?在本文中我们不是在讨论微服务架构,也不是讨论基础设施架构,这里的架构指:
- 在单个应用(进程)中
- 代码是如何组织起来实现一个端到端的用户请求的
- 它与框架无关,不管你是使用ORM框架或是JDBC,这不是架构的关键差异点
一个例子是三层架构,展现层负责接收用户指令、渲染视图;业务逻辑层负责处理”业务逻辑”;数据层负责和数据库打交道,保存和读取数据。
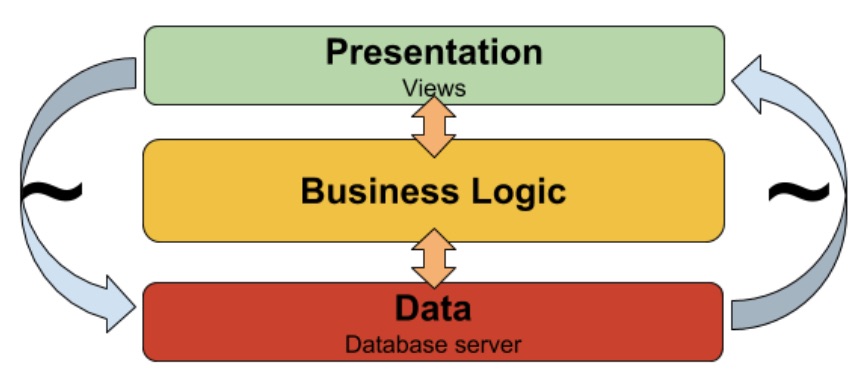
“经典”的三层架构
三层(或多层)架构仍然是目前最普遍的架构,但它也有缺点:
- 架构被过分简化,如果解决方案中包含发送邮件通知,代码应该放置在哪些层里?
- 它虽然提出了业务逻辑隔离,但没有明确的架构元素指导我们如何隔离
因此,在实际落地时,业务逻辑容易泄漏到展示层中,导致当应用需要一种新的使用方式时(例如开放API),原有的业务逻辑层可能不能快速重用,同样的问题也发生在数据层和业务逻辑层之间。
那么有没有替代的方案?Alistair Cockburn是敏捷运动的早期推动者之一,他于2005年在其博客中提出了端口和适配器架构,他对该架构的一句话定义是:
“应用应能平等地被用户、其他程序、自动化测试或脚本驱动,也可以独立于其最终的运行时设备和数据库进行开发和测试”
(原文为”Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.“)
该架构由端口和适配器组成,所谓端口是应用的入口和出口,在许多语言中,它以接口的形式存在。例如以取消订单为例,“发送订单取消通知”可以被认为是一个出口端口,订单取消的业务逻辑决定了何时调用该端口,订单信息决定了端口的输入,而端口为预订流程屏蔽了通知发送方式的实现细节。
而适配器分为两种,主适配器(别名Driving Adapter)代表用户如何使用应用,从技术上来说,它们接收用户输入,调用端口并返回输出。Rest API是目前最常见的应用使用方式,以取消订单为例,该适配器实现Rest API的Endpoint,并调用入口端口CancelOrderService。同一个端口可能被多种适配器调用,例如CancelOrderService也可能会被实现消息协议的Driving Adapter调用以便异步取消订单。
次适配器(别名Driven Adapter)实现应用的出口端口,向外部工具执行操作,例如
-
- 向MySQL执行SQL,存储订单
- 使用Elasticsearch的API搜索产品
- 使用邮件/短信发送订单取消通知
若将其可视化,Driving Adapter和Driven Adapter基于端口围绕着应用形成左右结构,有别于传统的分层形象,形成一个六边形,因此也会称作六边形架构
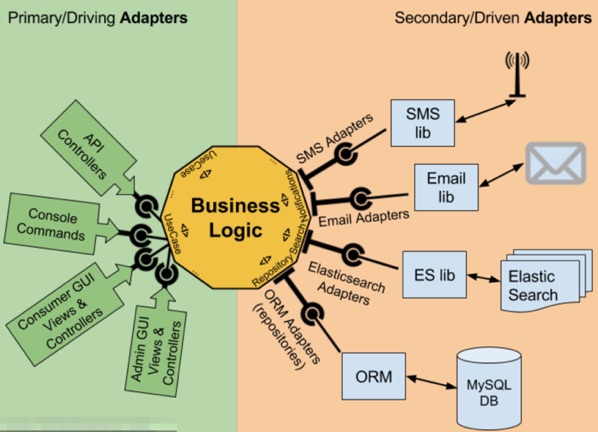
可视化端口和适配器架构
如果到此我已经成功地把你讲晕了,请不要担心,我们接下来通过一个案例体验一下这个架构。
端口和适配器架构有什么好处
DDD邮轮,有咨询公司的报告显示,在接下来的几年内,邮轮游作为国人出游形式的比例会大幅上升,在这样一个大背景下,DDD Cruise,一家中国的邮轮公司,正在研发新一代的预订系统,尝试在线邮轮预订。
目前计划中有两个触点应用:
- 微信小程序——提供邮轮搜索、邮轮预订的核心体验
- 中国区官网——这原是一个包含几个HTML页面的遗留应用,本次希望可以提供邮轮搜索的功能,值得注意的是,有部分邮轮是承包给旅行社销售,在网站上也需要展示以便做市场宣传
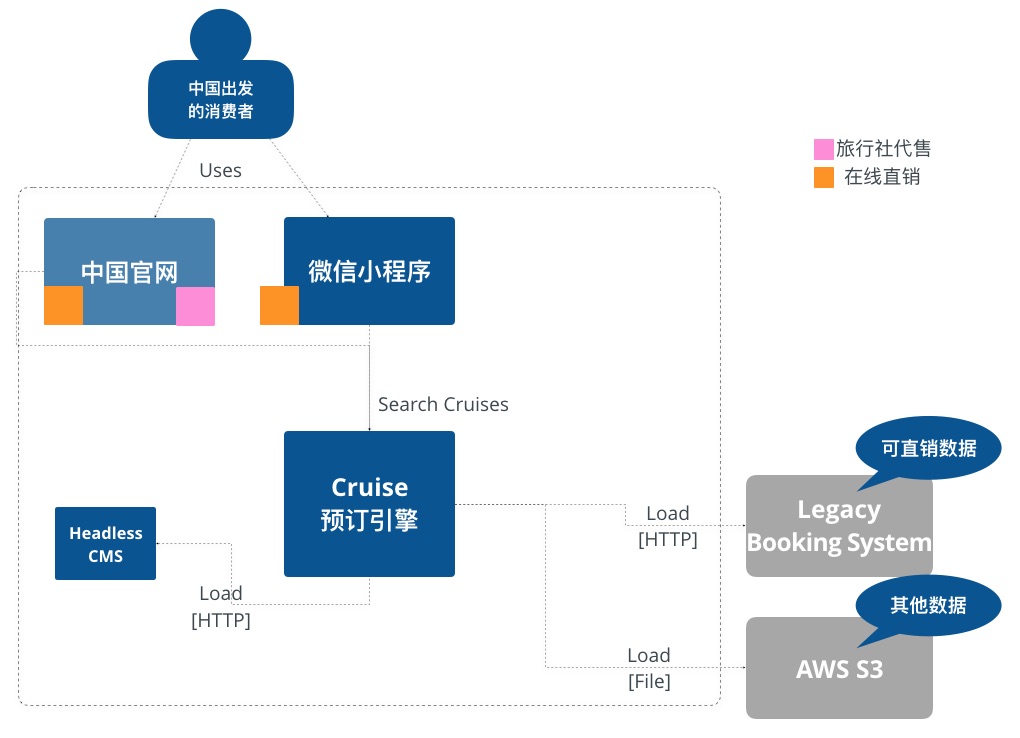
C4 Model——System Context Diagram
在这两个触点背后,是这次的主角,预订引擎1.0,计划以一个单体应用起步,为触点应用提供API,实现邮轮搜索、邮轮预订。邮轮有多个数据来源,一部分来自一个遗留的预订系统,一部分来自业务部门的Excel表格,存放在AWS S3对象存储中。最后还有一个小型的Headless CMS为市场人员提供邮轮描述,吸引眼球。
现在让我们代入端口和适配器:
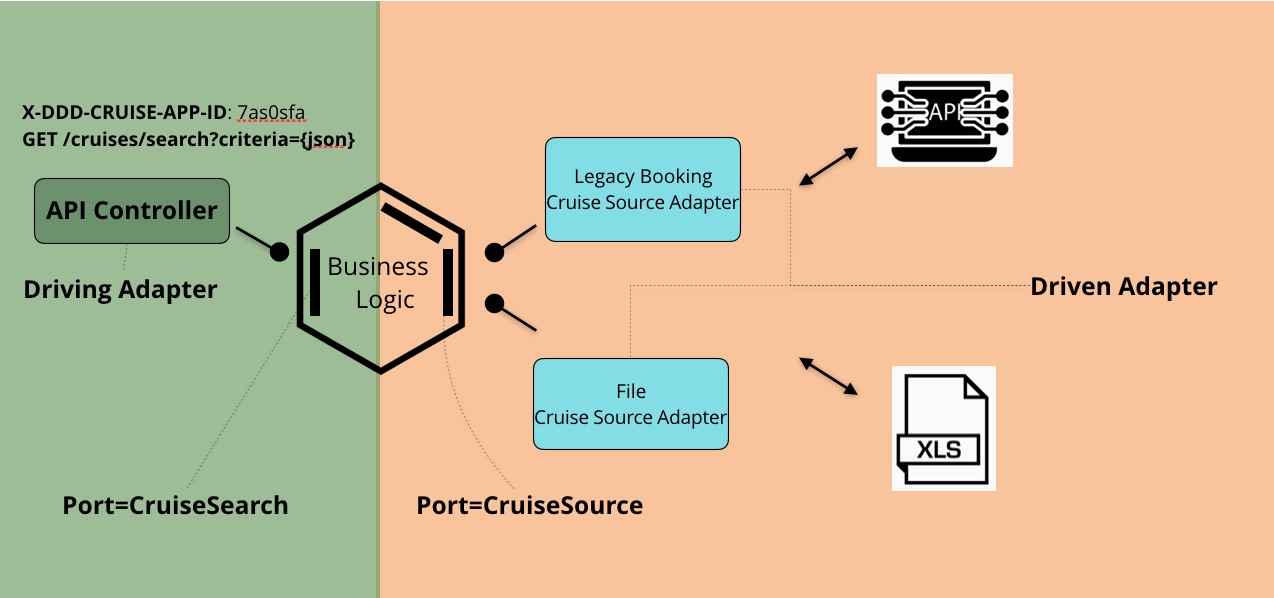
上“套路”,Driving Adapter一个,端口两个,Driven Adapter两个,连线少许
- API Controller是一个典型的Driving Adapter,它实现Rest API的Endpoint,调用入口端口CruiseSearch
- CruiseSearch作为应用的入口,向Driving Adapter屏蔽了邮轮搜索的实现。
- 在另一边,出口端口CruiseSource要求返回全量的Cruise数据,为应用隐藏了外部数据源的集成方案:从遗留预订系统或AWS S3上的文件中抽取Cruise
促进单一职责原则
那么我们接下来在这个架构的基础上,进行概要设计,组件很自然地分为了三个部分:
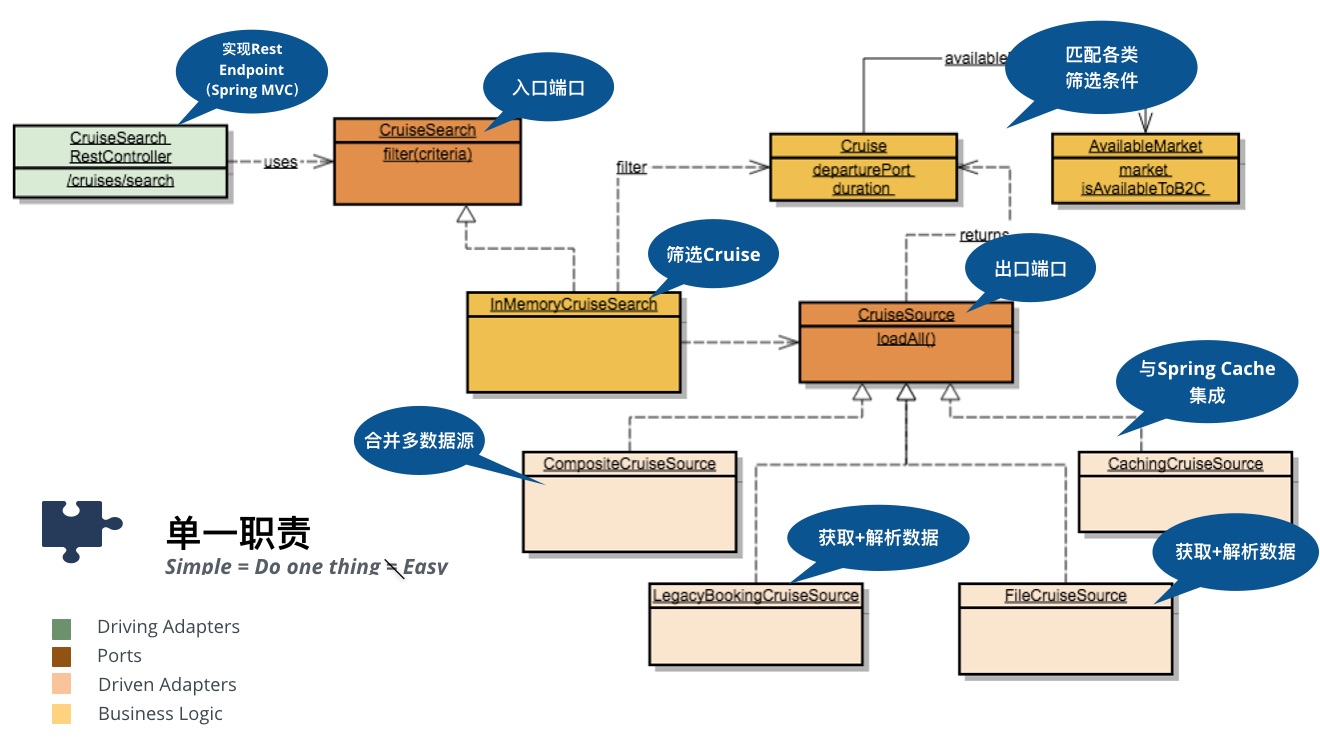
概要设计类图
-
绿色是Driving Adapter,如果你对Java-Spring技术栈,可以从命名发现他是一个RestController
-
黄色是Cruise Search的实现,这里的概念只和邮轮相关,你在这里不应该看到技术术语
-
粉色部分则是Driven Adapter,除了与处理从数据源获取Cruise的Adapter,我们还需要
a. CompositeCruiseSource,它不直接与数据源打交道,但它负责合并多个数据源并根据规则去除重复的Cruise b. CachingCruiseSource,它也不直接与数据源打交道,负责缓存Cruise
从架构角度来看,这些组件很简单。请注意,简单(Simple)并不代表着容易(Easy),简单说的是只做一件事(或一种事),而容易是指做一件事的难度,例如如果使用Spring MVC实现Driving Adapter,利用注解寥寥几行代码就可以实现。由于这些组件要么实现业务逻辑,要么实现对某种技术的适配,符合单一职责原则,你可以更有效地将变更控制在某一个范围内,更有信心地应对变化。
澄清测试策略
应对变化的另一个有效手段是自动化测试,测试金字塔是最常被提及的测试策略,它建议自动化测试集应该由大量单元测试作为基础,它们编写容易、运行速度快,应该只包含少量的用UI驱动的测试,由于需要处理测试数据冲突、外部依赖准备,它们编写困难、运行速度也较慢。但中层的service/集成测试的测试目标是什么,它们和单元测试有什么区别呢?
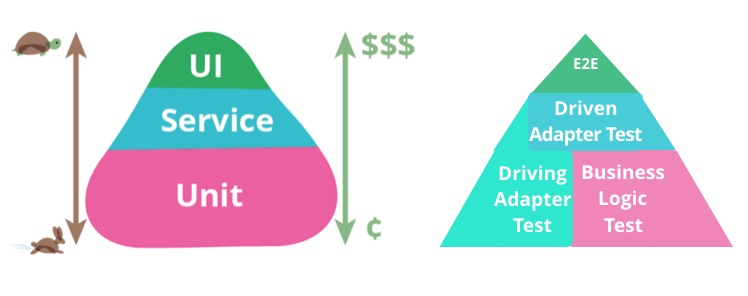
测试金字塔——端口和适配器版
如果你也有此困惑,不妨按照端口和适配器架构来重新解读,金字塔应该包含大量的Driving Adatper测试、业务逻辑测试、Driven Adapter测试。
- Driving Adapter测试,目标是验证API能正确地解析输入、按预期的参数调用了入口端口并生成输出。由于Driving Adapter不关心入口端口的实现,在测试中,可以通过Mock方便地构造测试场景,并提升测试速度。
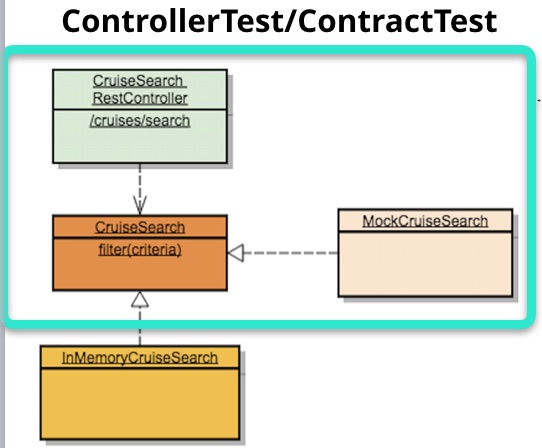
近两年开始流行的契约测试也可以认为是Driving Adapter测试的扩展
- 业务逻辑测试,通过Mock出口端口,同样可以方便地构造测试数据,而且这里应该都是Plain Object,测试可以完全在内存中运行,速度是最快的
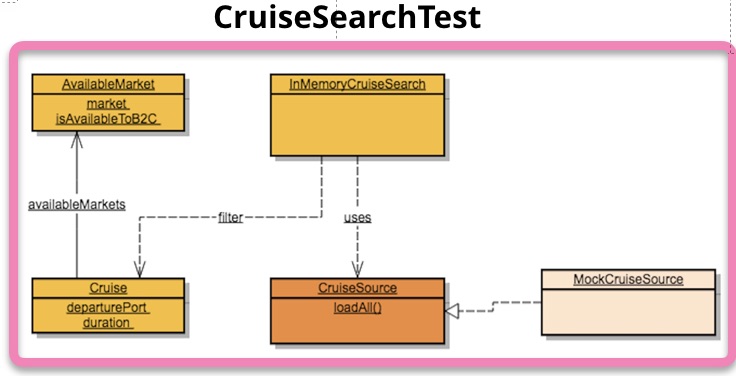
传统的单元测试
- Driven Adapter测试,目标是验证按预期的方式操作了外部工具、下游服务、数据库。传统上,涉及这些外部依赖的测试编写难度大,运行速度慢,但如果出口端口和Driven Adapter设计得当,它们就不涉及业务逻辑,从而需要测试用例会大大减少,通过引入内存数据库、Stub Server等技术,其测试场景的构建难度会改善不少,整体执行时间也会相应减少
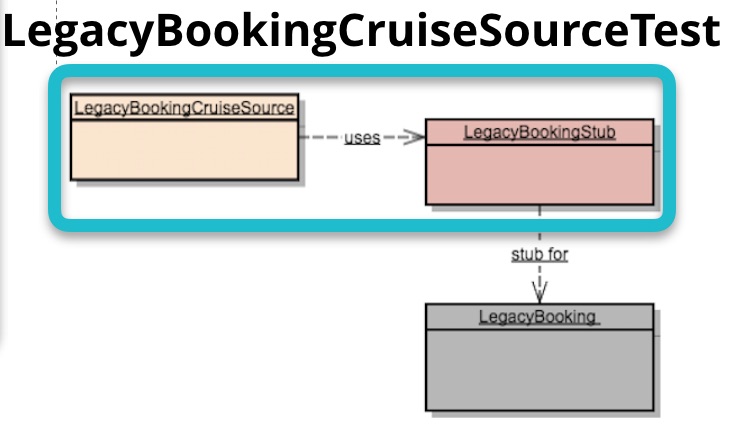
单一职责的Driven Adapter也降低了测试难度,不过测试速度仍然相对较慢
需要注意的是以上测试都是在技术上检测组件是否符合预期,可以考虑适当加入E2E Test来验证这些组件集成起来可用,业务上符合预期,一般覆盖关键功能的Happy Path场景即可。
促进增量开发
端口和适配器架构可能还能给与我们一些灵感,实施增量开发,不妨看一下这个用户故事分解的例子:
由于旅行社代售的邮轮都来自于Excel表格,只要确定了表格字段含义,我们就可以开始集成,我们选择这张卡来搭建脚手架:
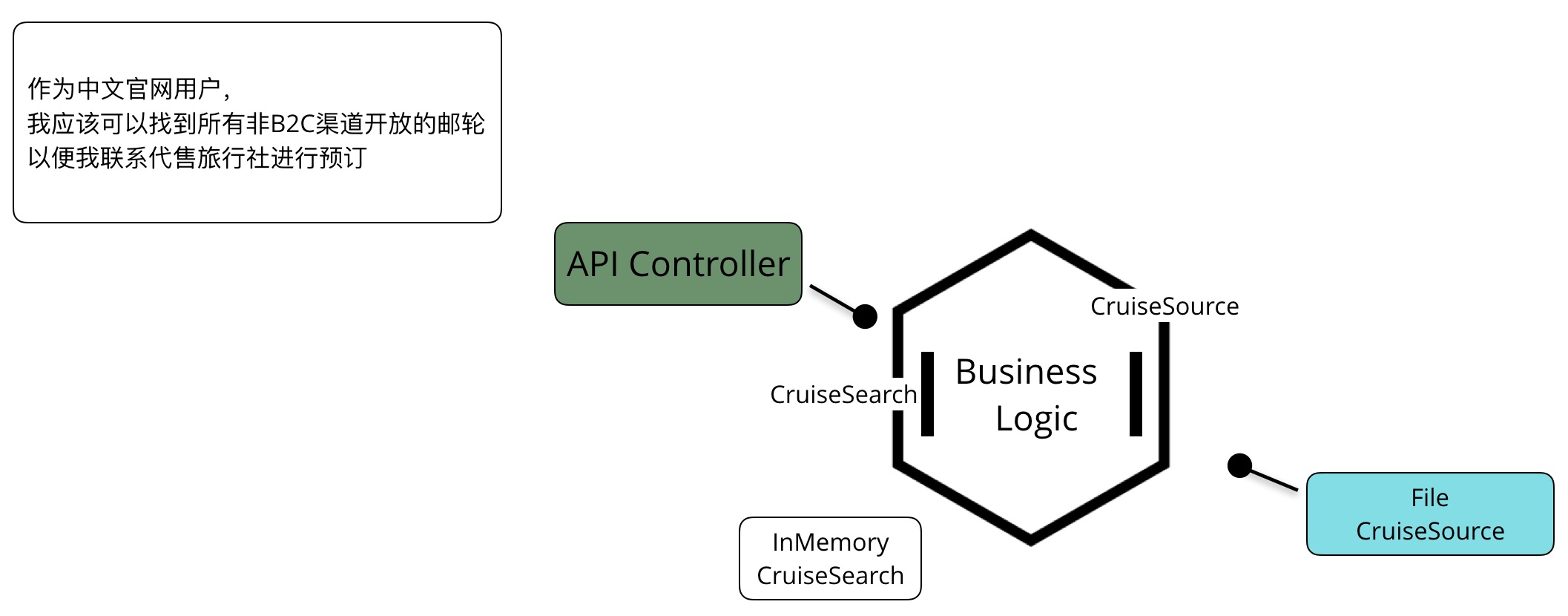
如果业务优先级允许,选择技术实现最简单的卡搭建脚手架
接下来在InMemoryCruiseSearch中实现筛选:
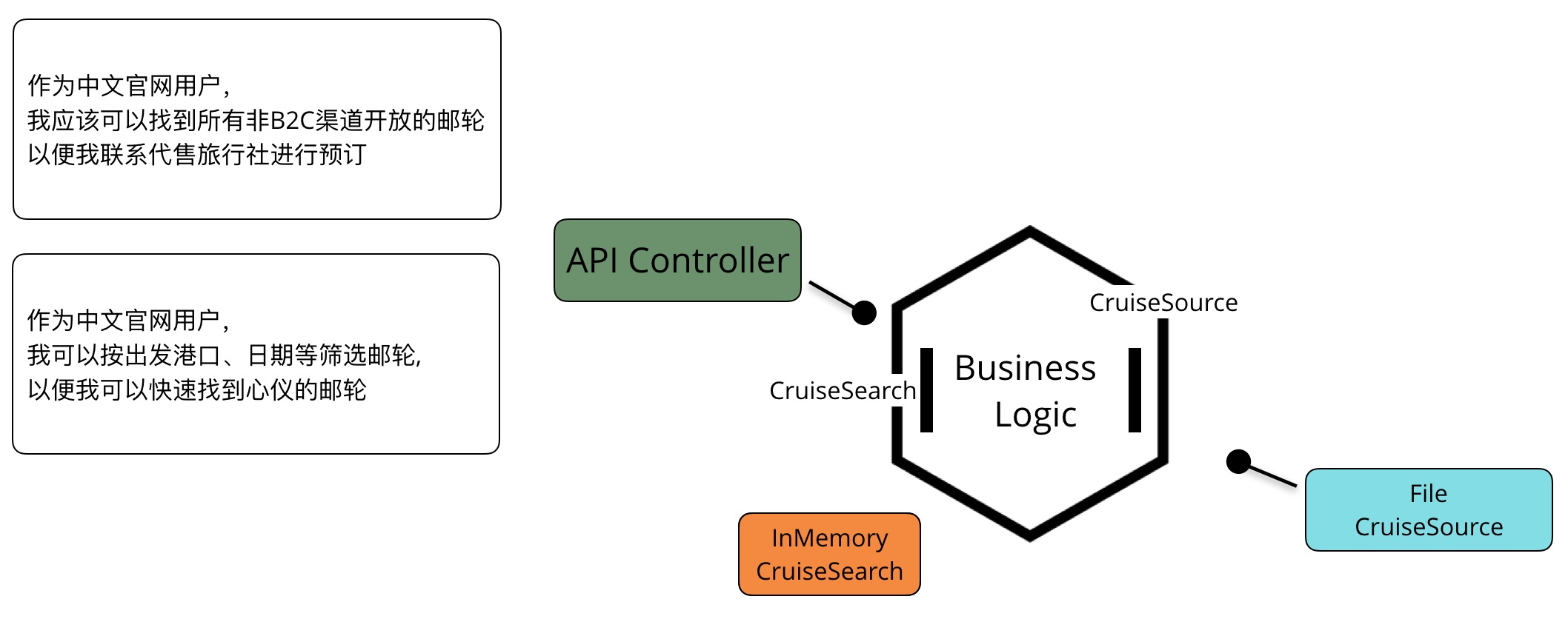
实现筛选功能
引入LegacyBookingCruiseSource和CompositeCruiseSource
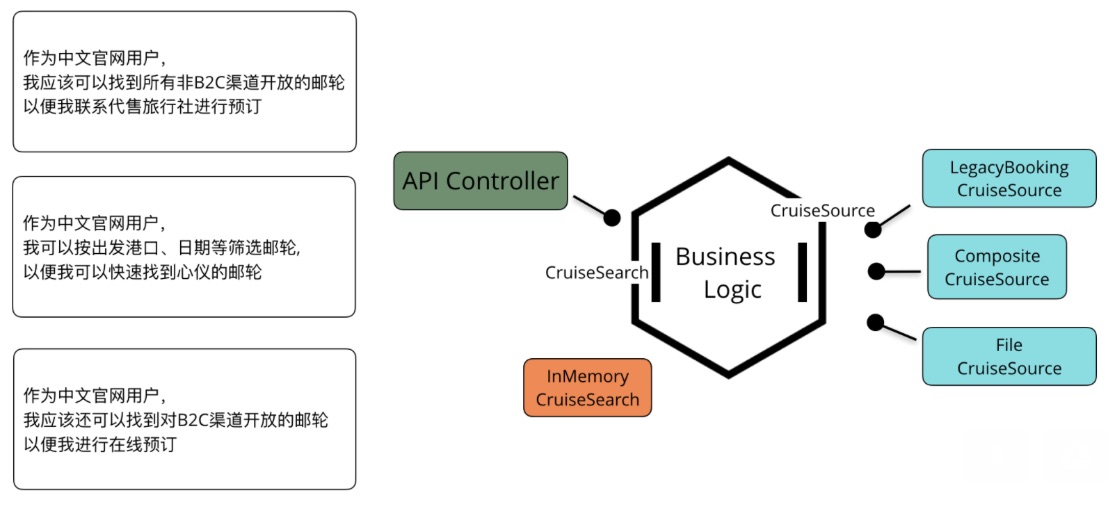
扩展数据源,另外还需要扩展Cruise销售渠道的筛选条件实现
最后,可以引入一张技术卡:
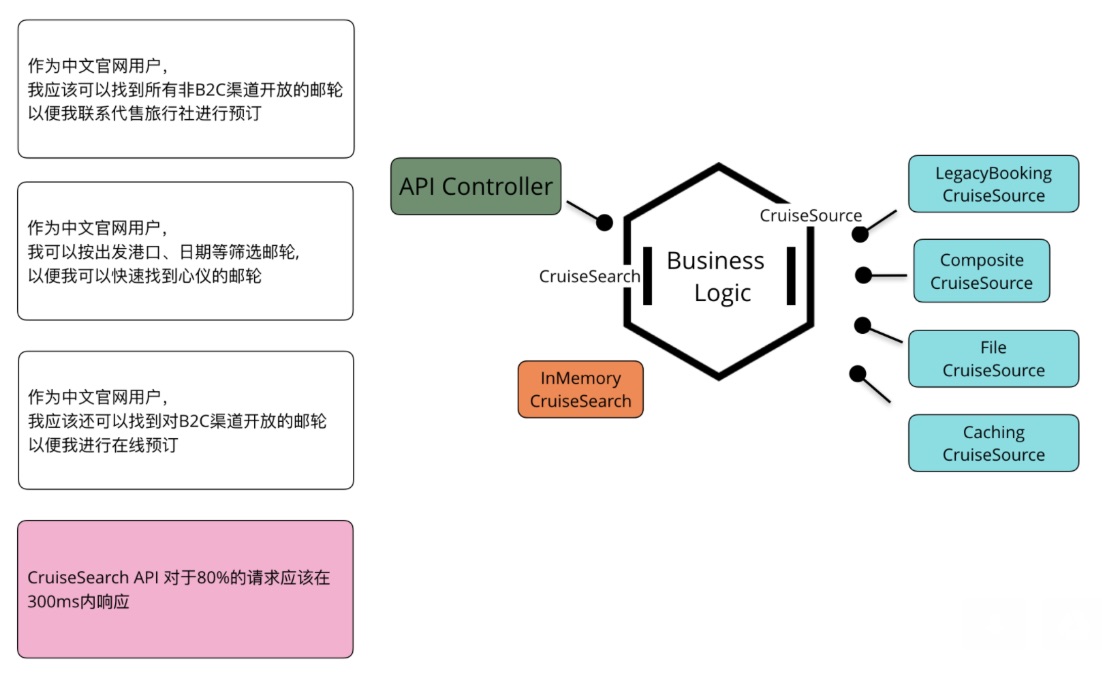
加入CachingCruiseSource,提升Cruise读取速度
到这里,我们不妨小结一下:
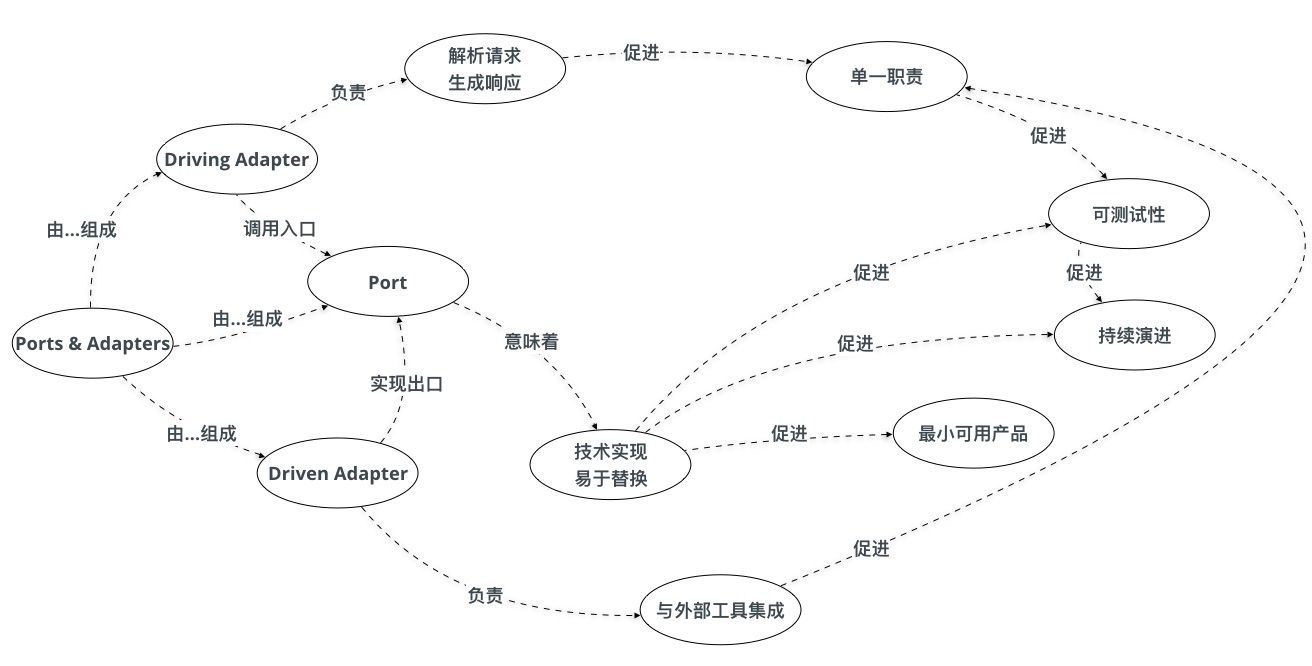
端口和适配器架构的组成元素及它的好处
与领域驱动设计的协同增效
由于概念简单、易于掌握,端口和适配器架构很适合作为DDD的入门辅导工具,而领域驱动设计的诸多方法也能够补充端口和适配器架构的空白,形成合力。
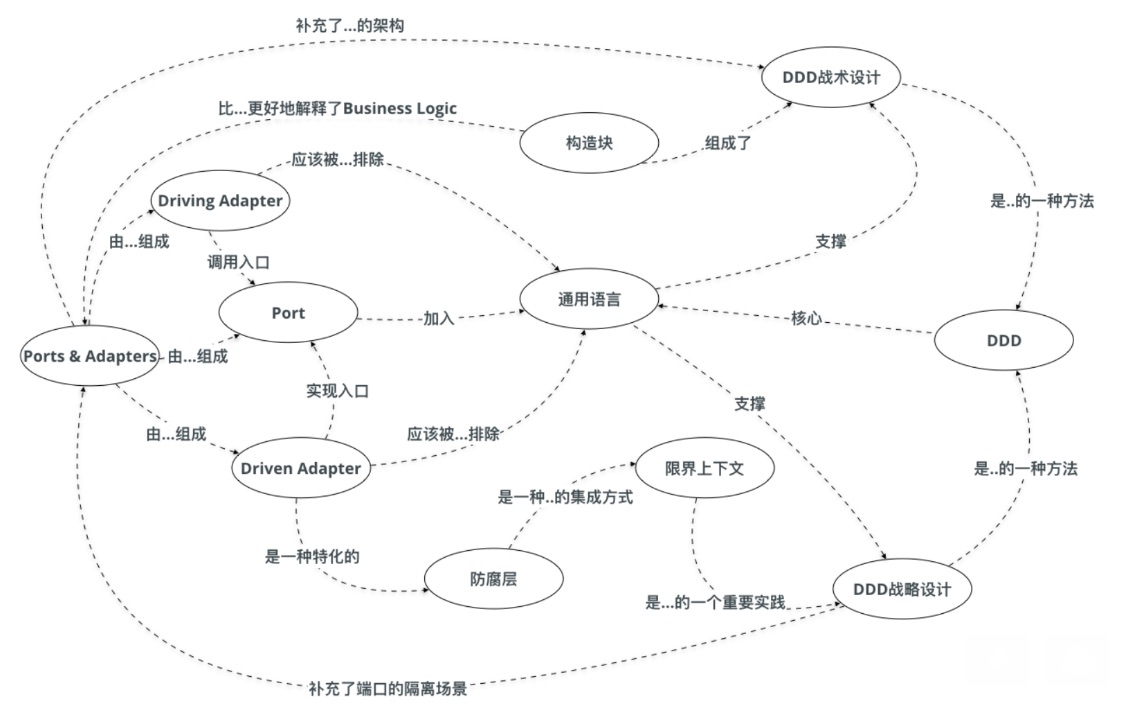
端口和适配器架构与领域驱动设计的协同增效
校验“通用语言”
通用语言是领域驱动设计的核心精髓,它建议各方(无论是领域专家和还是开发人员)对于同一件事都使用相同的词汇。这可以防止各方在沟通领域问题、制定解决方案时不会由于不同的专业背景产生误解,最终促进了识别正确的问题,采用正确的解决方案。甚至有激进的观点认为“领域模型就是通用语言本身”。
端口和适配器虽然不能直接帮助我们找到领域模型或通用语言,但它有助于我们从通用语言中快速剔除技术概念:凡是用于实现适配器的技术细节都应该被排除。让我们回到DDD Cruise的例子:

对话片段,注意绿色字体都和Driven Adapter有关,它们应该被通用语言排除
作为“DDD战术设计”的脚手架
领域驱动设计于2004年横空出世,一年后端口和适配器被提出,在战术设计层面,我们可以发现诸多相似点,互为呼应。以架构为例,DDD原著中提出的架构很有意思:乍看之下,以为是传统的分层架构,但却强调了Infrastructure对各层的实现。

如果我们做一下职责分析,你会发现这不就是端口和适配器嘛?
端口和适配器的优势是突出了分层不是重点,技术实现隔离才是关键,让你不再纠结是否允许组件跨层调用。而DDD原著架构的优势是用Application和Domain进一步澄清了业务逻辑这个模糊的概念。不妨合二为一:
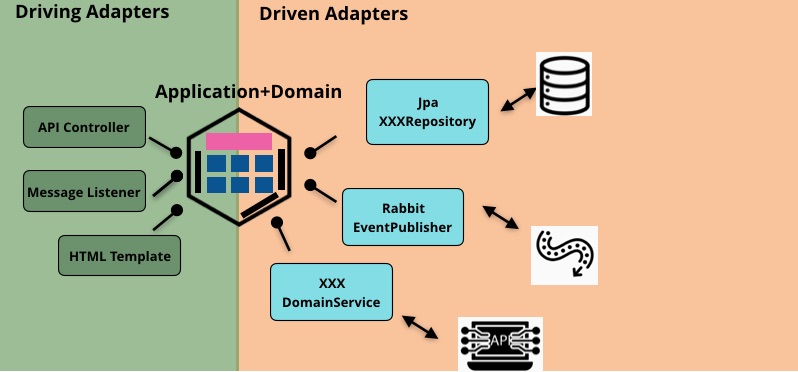
值得一提的是,Application和Domain甚至可以是声明式的,作为端口存在,例如DDD构建块中的ApplicationService是一个典型的入口端口,而Repository则是一个典型的出口端口。
让我们回到DDD Cruise,细化Cruise的领域模型:CruiseSearch(应用服务),但实际的筛选逻辑会交给Cruise(实体)及其值对象Itinerary,Leg实现,你甚至可以引入DDD书中提到的规格模式,进一步强化单一职责,将筛选条件与领域模型筛选方法的映射工作从InMemoryCruiseSearch中剥离,使其完全只负责步骤协调
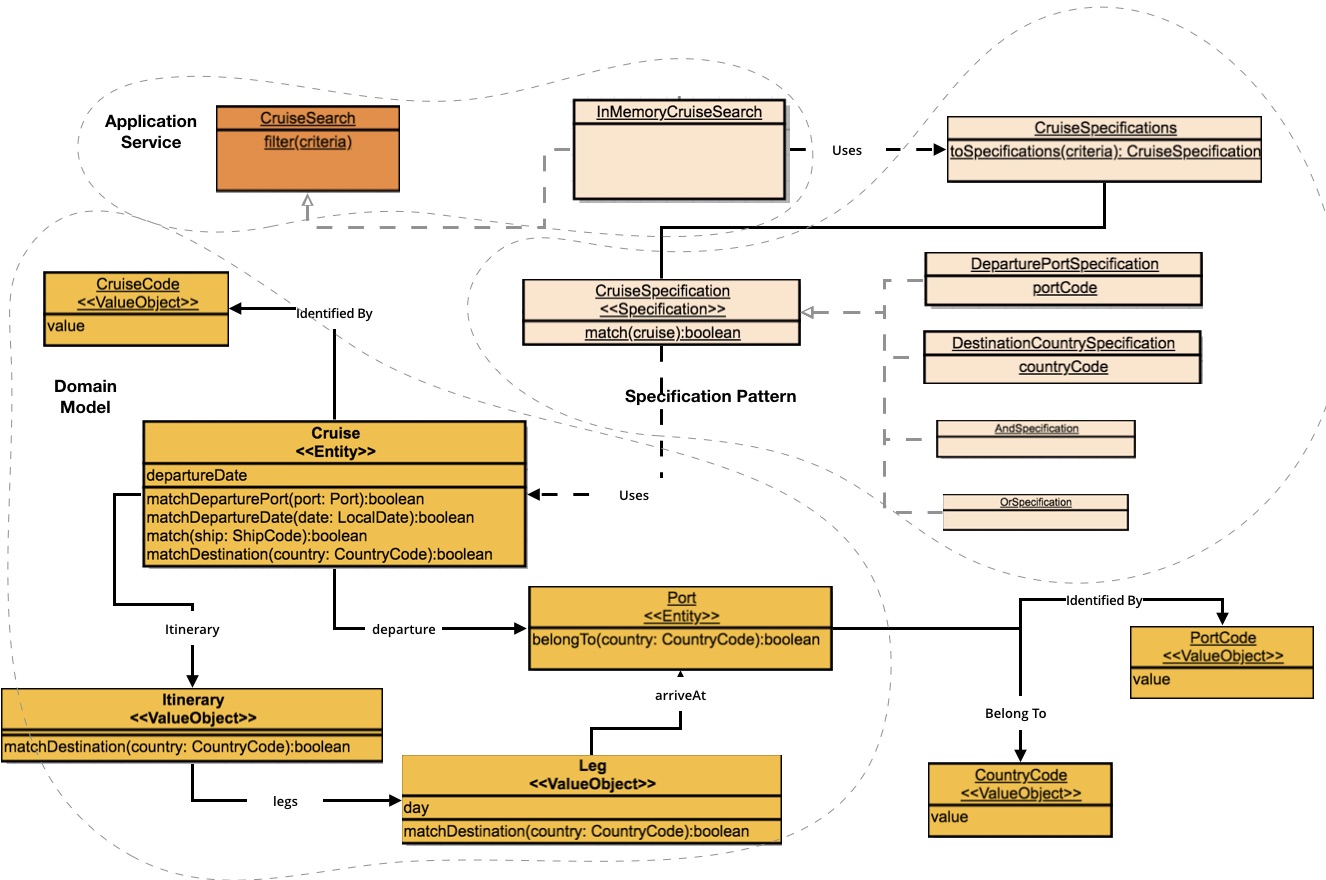
将应用服务、领域模型代入Cruise Search
让“DDD战略设计”指导隔离实施
实施战略设计时候,有一个重要的实践是限界上下文的识别,当存在多个限界上下文的时候,很有可能需要集成,防腐层是常见的集成手段。 来看这个示意:Service A 是左侧限界上下文暴露出来的接口,通过适配器调用右侧限界上下文的接口。
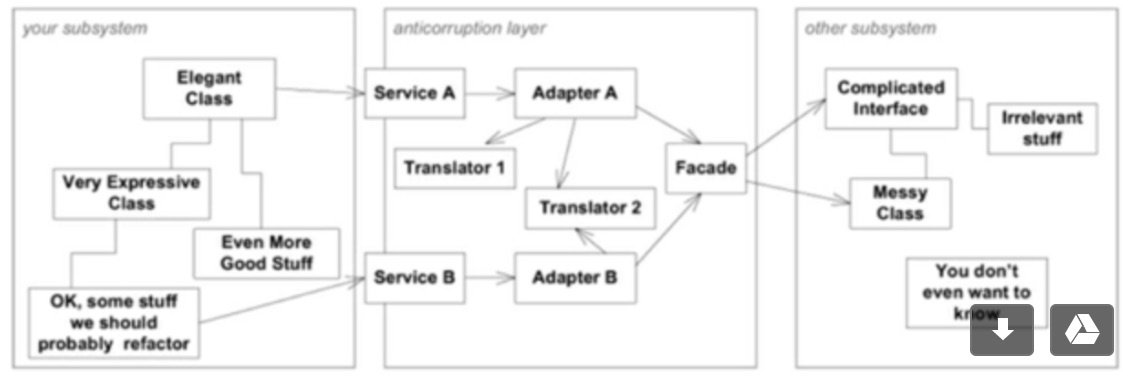
“防腐层”
这是不是很眼熟?这不正是端口和Driven Adapter吗?你可以认为它们是一种特化的防腐层。 那么当一个单体应用中有多个限界上下文时,它们之间也应该用端口隔离,用适配器集成。如果你使用微服务来隔离限界上下文,端口和适配器架构则适用于其中每个服务。
回到DDD Cruise,还记得我们需要集成Headless CMS吗,由于在当前阶段,我们工作在单体应用中,CruiseSearch的API需要返回包含邮轮描述的信息。
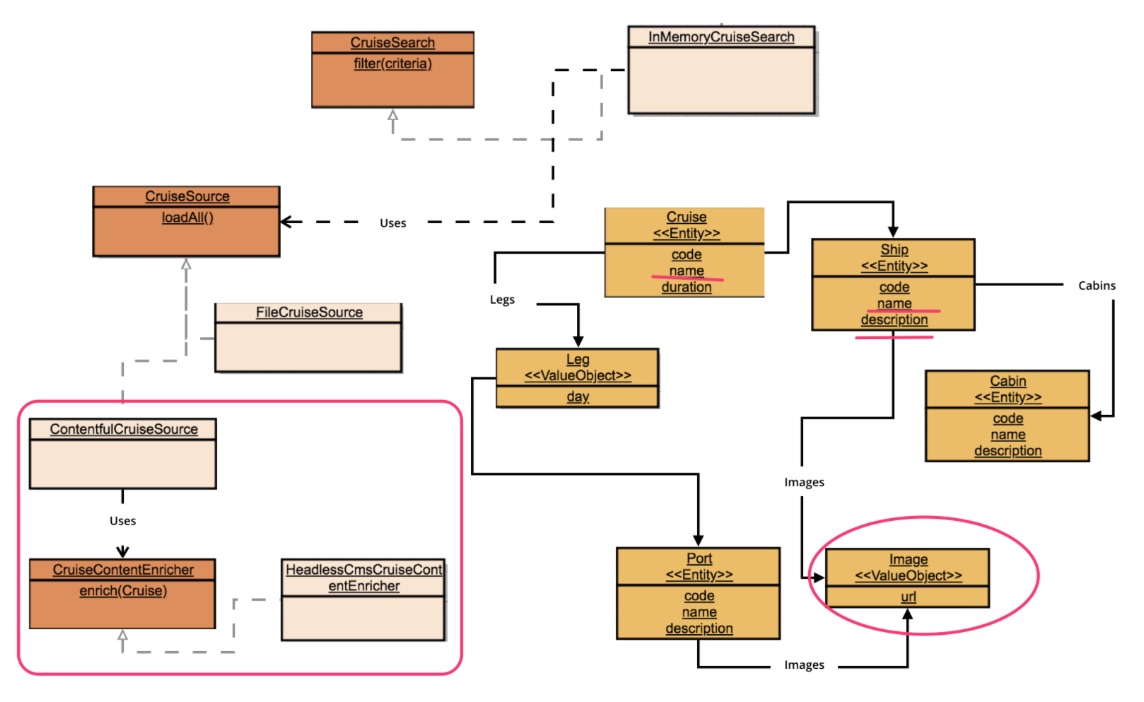
没有识别限界上下文,虽然引入了端口和Driven Adapter,但不够理想
一种方案是将这些描述信息加入到领域模型中,由于已有的两个数据源都无法提供这些信息,我们又引入了ContentfulCruiseSource及另一个出口端口CruiseContentEnricher及其Driven Adapter以便填充这些信息。但这个方案不够理想:
- 在邮轮搜索的筛选实现中,描述信息并没有实际作用,领域模型变得更臃肿了,甚至造成了干扰
- 在邮轮搜索的测试中,我们并不关心这些描述信息,但却可能需要构造一些Dummy数据,避免可能的空指针误报
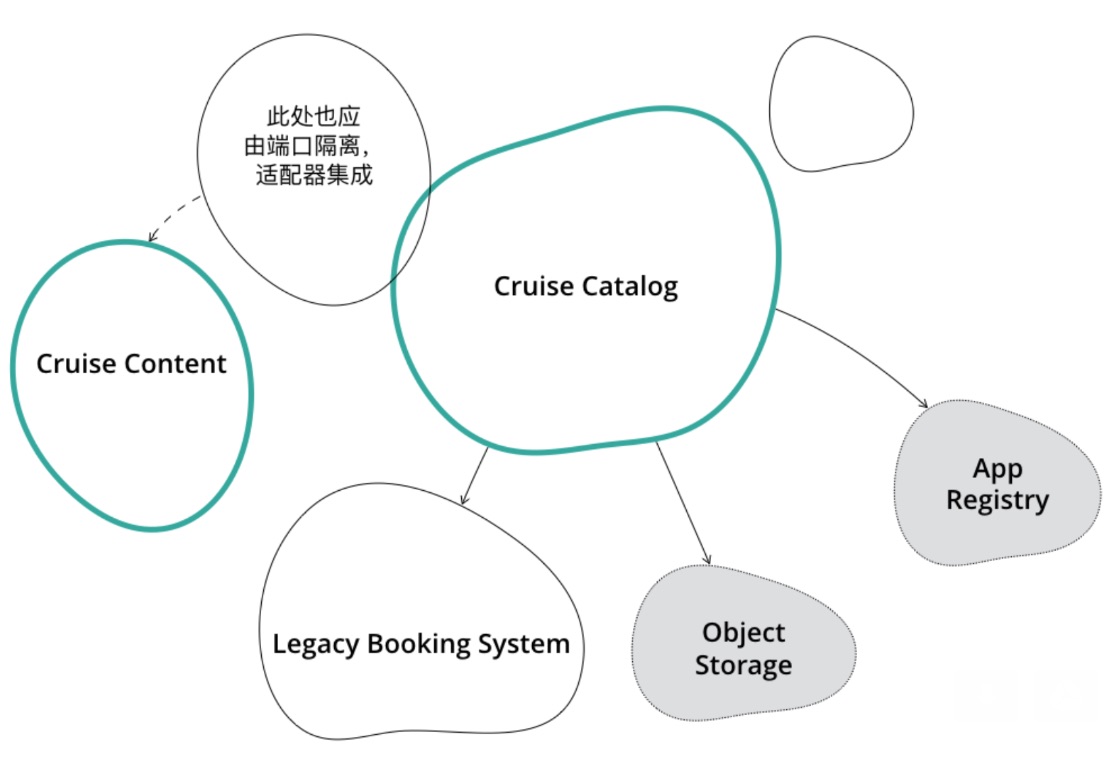
将限界上下文引入DDD Cruise
在限界上下文概念指导下的另一种方案,引入CruiseContentEnricher既作为入口端口、同时也作为出口端口,保持邮轮搜索上下文不被干扰,这个方案的好处是,假设邮轮搜索引擎进行微服务改造,很有可能将描述信息填充的职责分离到单独的服务中去,这时,只需要再提供一个输入、输出不含描述信息的Driving Adapter就可以了。
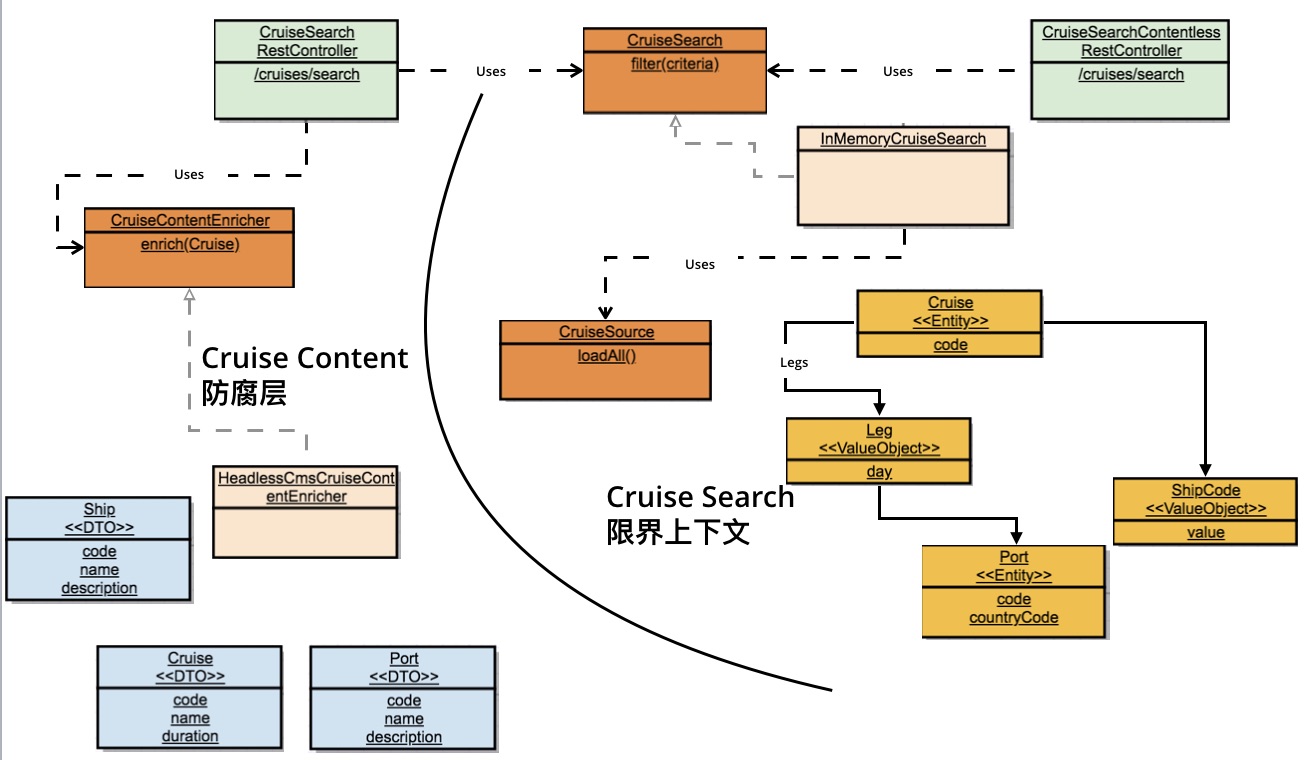
在限界上下文指导下找到更稳定的端口
总结
我们介绍了端口和适配器架构,它简单易掌握,和领域驱动设计又合拍,希望它能帮助你快速积累DDD经验!
单页应用的HATEOAS实战

要点
- HATEOAS是Hypertext As The Engine Of Application State的缩写。在 Richardson Maturity Model中, 它是REST的最高级形态
- 单页应用正越来越受到欢迎,前后端分离的开发模式进一步细化了分工,但同时也引入了不少重复的工作,例如一些业务规则在后端必须实现的情况下,前端也需要再实现一遍以获得更好的用户体验。HATEOAS虽然不是唯一消除这些重复的方法,但作为一种架构原则,它更容易让团队找到消除重复的“套路”
什么是HATOEAS
HATEOAS是Hypertext As The Engine Of Application State的缩写。采用Hypermedia的API在响应(response)中除了返回资源(resource)本身外,还会额外返回一组Link。 这组Link描述了对于该资源,消费者(consumer)接下来可以做什么以及怎么做。
举例来说,假设向API发起一次get请求,获取指定订单的资源表述(representation),那么它应该长得像这样:
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Content-Type: application/hal+json;charset=UTF-8
Transfer-Encoding: chunked
Date: Fri, 05 Jun 2015 02:54:57 GMT
{
"tracking_id": "123456",
"status": "WAIT_PAYMENT",
"items": [
{
"name": "potato",
"quantity": 1
}
],
"_Links": {
"self": {
"href": "http://localhost:57900/orders/123456"
},
"cancel": {
"href": "http://localhost:57900/orders/123456"
},
"payment": {
"href": "http://localhost:57900/orders/123456/payments"
}
}
}- 理解Link中的“self”的消费者知道使用get方法访问其“href”的uri可以查看该订单的详细信息
- 理解Link中的“cancel”的消费者知道使用delete方法访问其“href”的uri可以取消该订单
- 理解Link中的“payment”的消费者知道使用post方法访问其“href”的uri可以为该订单付款
REST是目前业界相当火热的术语,似乎发布的API不带个REST前缀,你都不好意思和别人打招呼了。 然而大部分号称REST的API实际上并没有达到Richardson成熟度模型的第三个级别:Hypermedia。 而REST的发明者Roy Fielding博士更是直言HATEOAS是REST的前提, 这不是一个可选项,如果没有Hypermedia,那就不是REST。(摘自Infoq对Fielding博士的第二段访谈)
那么HATOEAS带来了什么优势?
一个显而易见的好处是,只要客户端总是使用Link Rel来获取URI,那么服务端可以在不破坏客户端实现的情况下实现URI的修改,从而进一步解耦客户端和服务端。
另一个容易被忽视的优势是它可以帮助客户端开发者探索API,Links实际上提示了开发者接下来可以进行何种业务操作,开发者虽然精通技术,但往往对于业务不甚了解,这些提示可以帮助他们理解业务,至少是一个查询API文档的好起点。想象一下,如果某个API的响应中多了一个新的Link,敏感的开发者可能就会询问这个Link是用来做什么的,是一个新的特性吗?虽然看起不起眼,但这往往使两个团队的成员沟通起来更容易。
单页应用和HATEOAS
在过去的几年里,WEB开发技术发生了很多重大的变革,其中之一就是单页应用,它们往往能带来更平滑的用户体验。在这一领域,分工进一步细化,前端工程师专精客户端程序构建和HTML、CSS等效果的开发,后端工程师则更偏重高并发、DevOps等技能,大部分特性需要前后端工程师配合完成。或许有人会质疑,为什么不是全栈工程师?诚然,如果一个人就能端到端的交付特性,那自然会减少沟通成本,但全栈工程师可不好找,细化分工才能适应规模化的开发模式。继Ajax之后,单页应用和前后端分离架构进一步催生了大量的API,我们急需一些方法来管理这些API的开发和演进,而HATEOAS应该在此占有一席之地。
在摸索中前进,自由地重命名你的资源
我们常说在敏捷开发中,应该拥抱变化。所以敏捷开发中推崇重构、单元测试、持续集成等技术,因为它们可以使变化更容易、更安全。HATOEAS也是这样一种技术。想象一下,在项目初始阶段,团队对业务的理解还不深入,很有可能会得出错误的业务术语命名,或者业务对象的建模也不完全合适。反映在API上,可能你希望能够修正API的URI,在非HATOEAS的项目中,由于URI是在客户端硬编码的,即使你把它们设计的非常漂亮(准确的HTTP动词,以复数命名的资源,禁止使用动词等等),也不能帮助你更容易地修改它们,因为你的重构需要前端开发者的配合,而他/她不得不停下手头的其他工作。但在采用了HATEOAS的项目中,这很容易,因为客户端是通过Link来查找API的URI,所以你可以在不破坏API Scheme的情况下修改它的URI。当然,你不可能保证所有API的URI都是通过Link来获取的,你需要安排一些Root Resource,例如 /api/currentLoggedInUser,否则客户端没有办法发起第一次请求。
HTTP/1.1 200 OK
Path: /api/currentLoggedInser (1)
{
…… //omitted content
"_Links": { (2)
"searchUserStories": {
"href": "http://localhost:8080/userStories/search{?page, size}"
},
"searchUsers": {
"href": "http://localhost:8080/users/search{?page, size, username}"
},
"logout": {
"href": "http://localhost:8080/logout"
}
}
}- Root Resource,它们是API的入口,客户端通过他们浏览当前用户有哪些资源可以访问,你可以定义多个Root Resource,并确保它们的URI不会改变
- Link引入的URI可以自由地变化,可能是因为需要重命名资源,也可能是需要抽取出新的服务(域名变化)
消除重复的业务规则校验实现,更容易得适应变化
经验告诉我们,不能相信客户端的请求,所以在服务端我们需要根据业务规则校验当前的请求是否合法。这样确保了业务正确,但当用户发起了请求后才告诉他们请求失败,有时候是一件令人沮丧的事情。为了用户体验,可能会要求某些组件根据业务规则展示。例如,对于某个业务对象,要求编辑按钮只在当前用户可以编辑的情况下才展示。在传统的服务端渲染架构下,一般都可以复用校验的代码,而在单页应用中,往往由于技术栈不同,代码无法直接共用,业务规则在前后端都分别实现了一次。例如,在我们最近的一次项目中,前后端分别实现了如下规则:
给定一个用户故事,
只有它的作者才能编辑它
服务端通过在用户故事的API中暴露作者帮助前端完成编辑按钮的有条件渲染。
HTTP/1.1 200 OK
Path: /api/userStories/123
{
"author": "john.doe@gmail.com" (1)
}- 与当前用户比较判断是否渲染编辑按钮
但如果规则发生变化,前后端都需要适应这一改变,所以我们用HATEOAS重构了一下:
HTTP/1.1 200 OK
Path: /api/userStories/123
{
"author": "john.doe@gmail.com",
"_links": {
"updateUserStory": { "href": "http://localhost:8080/api/userStories/123" } (1)
}
}- 现在前端会根据
updateUserStorylink是否出现来验证当前用户是否具有编辑用户故事的能力
后来业务规则变为除了作者之外,系统管理员也可以编辑用户故事,这时候只需要后端去响应这个变化就行了。你可能会质疑,通过为用户故事暴露一个 isCurrentLoggedInUserAvailableToUpdate的计算属性也可以做到。没错,HATOEAS并不是唯一的办法,但作为一种架构约束,团队会自然而然地想到它,而计算属性则要求团队成员有更强的抽象技能。
总结
HATEOAS提倡在响应返回Link来提示对该资源接下来的操作。这种方式解耦了服务端URI,也可以让客户端开发者更容易地探索API。最后,通过Link来判断业务状态,还能有效地消除单页应用中的业务规则重复实现。