从消费者的角度评估REST的价值
REST是目前业界相当火热的术语,似乎发布的API不带个REST前缀,你都不好意思和别人打招呼了。 然而大部分号称REST的API实际上并没有达到Richardson成熟度模型的第三个级别:Hypermedia。 而REST的发明者Roy Fielding博士更是直言“Hypermedia作为应用引擎”是REST的前提, 这不是一个可选项,如果没有Hypermedia,那就不是REST。(摘自Infoq对Fielding博士的第二段访谈)
什么是Hypermedia?
那究竟什么是Hypermedia? 采用Hypermedia的API在响应(response)中除了返回资源(resource)本身外,还会额外返回一组链接(link)。 这组链接描述了对于该资源,消费者(consumer)接下来可以做什么以及怎么做。
举例来说,假设向API发起一次get请求,获取指定订单的资源表述(representation),那么它应该长得像这样:
HTTP/1.1 200 OK
Server: Apache-Coyote/1.1
Content-Type: application/hal+json;charset=UTF-8
Transfer-Encoding: chunked
Date: Fri, 05 Jun 2015 02:54:57 GMT
{
"tracking_id": "123456",
"status": "WAIT_PAYMENT",
"items": [
{
"name": "potato",
"quantity": 1
}
],
"_links": {
"self": {
"href": "http://localhost:57900/orders/123456"
},
"cancel": {
"href": "http://localhost:57900/orders/123456"
},
"payment": {
"href": "http://localhost:57900/orders/123456/payments"
}
}
}- 理解链接中的“self”的消费者知道使用get方法访问其“href”的uri可以查看该订单的详细信息
- 理解链接中的“cancel”的消费者知道使用delete方法访问其“href”的uri可以取消该订单
- 理解链接中的“payment”的消费者知道使用post方法访问其“href”的uri可以为该订单付款
这看起来很有趣,然而这对API的消费者来说有什么好处呢?
不再揣测如何组合使用API
不知道在你的开发生涯中有没有遇到过这样的事情:
有一天,产品经理跟我说,我们要和某某酒店集团对接,在线销售它们的酒店,这是他们的联系人和详细的API说明文档。 API说明文档真够详细,有好几十页,凭着丰富的行业经验,我知道我需要找到其中的哪些API来实现基本的业务场景。 几天后,我实现了大部分的API集成,现在可以预订酒店了,订单已经在对方的测试环境生成,大功告成。 等等,这个“添加订单财务信息”的API是干嘛的?在和对方的联系人联系后,被告知“没什么用”,好了,真的大功告成了,上线!
两周后,我们的API使用权限被对方关闭了,原因是“所有的订单都没有财务信息,无法确认对账”。
“等等,那谁谁谁不是说这个API没用吗?”
“噢,他已经离职了,你们如果要恢复使用,尽快完成这个API的集成吧”
“我。。。”
当然,这里面还有许多别的因素,但是消费者的开发人员往往很难将业务场景和实现业务场景的API联系起来。 他们常常面对是:
- 不熟悉的业务场景
- 一套对单个API的作用描述详细,但缺乏API之间联系的文档。
Hypermedia带来的API自描述特性,使用链接的方式提示接下来做什么和怎么做,正好可以缓解这样的窘境。 如果API服务方可以提供测试环境供消费者测试,那么开发人员可以实际动手探索业务场景的衔接,这时再配合API文档情况就好多了。 回到酒店订单的例子,如果是这样,我可能就不会挨批了:
// 预订后,提示确认订单,那么不熟悉为什么要确认以及不确认的后果的同学就可以想到去问啦
{
"tracking_id": "123456",
"Hotel": "A ZHAO DAI SUO",
"status": "WAIT_ACKNOWLEDGED",
"_links": {
"self": {
"href": "http://zhaodaisuo.com/orders/123456"
},
"cancel": {
"href": "http://zhaodaisuo.com/orders/123456"
},
"acknowledge": {
"href": "http://zhaodaisuo.com/orders/123456/payments"
}
}
}// 确认后,提示添加财务信息,不熟悉的同学就可以问了,然而我真的已经问了呀。。。。
{
"tracking_id": "123456",
"Hotel": "A ZHAO DAI SUO",
"status": "ACKNOWLEDGED",
"_links": {
"self": {
"href": "http://zhaodaisuo.com/orders/123456"
},
"billing": {
"href": "http://zhaodaisuo.com/orders/123456/bill"
}
}
}从此与API版本说再见
不知道在你的开发生涯中有没有遇到过这样的事情:
有一天,产品经理跟我说,我们要实现一个新功能blablabla,但是依赖的API版本太老了,这是他们的联系人。
“你好呀,请问我们需要这个信息,但是现在1.3的版本中没有提供,有什么办法吗?”
“你可以升级到2.1的版本就有了”
“那这个版本是不是向后兼容的啊?我们用了其中很多接口哦,我不想其它的集成点出问题”
“那当然,放心吧”
结果当然是个悲伤的故事,“你给我过来,我保证不打死你”。 API的发布方也需要增加新功能,API自身也会随着需求变化,于是产生了版本号
http://www.zhaodaisuo.com/api/v1.2
然而一套API一般会包括多个API,为整套API版本化的粒度太粗了。 一旦消费者希望获得其中某个API的新特性,他/她只能选择全盘升级并仔细测试或者为每个集成点配置单独的uri。 这都不够好,而Hypermedia可以改变这种局面。 由于提供了链接来告诉消费者资源的uri,相对“传统”的REST API,uri变成了一种弱耦合, Hypermedia API只需要公布少量入口uri就可以了。比如,以之前酒店订单的例子,只需发布
http://www.zhaodaisuo.com/orders
后续的确认、财务信息的uri是在实际API调用的时候拿到的,无需事先准备。 消费者和发布者之间的强耦合实际上只剩下入口uri和服务契约(解释资源的含义), 当服务契约新增或是发生破坏性的变化时(例如修改了或删除了参数),只需要在资源表述中增加新的链接。
{
"tracking_id": "123456",
"Hotel": "A ZHAO DAI SUO",
"status": "ACKNOWLEDGED",
"_links": {
"self": {
"href": "http://zhaodaisuo.com/orders/123456"
},
"billing": {
"href": "http://zhaodaisuo.com/orders/123456/bill"
},
"billing-v1.1": { //billing发生了破坏性变化
"href": "http://zhaodaisuo.com/orders/123456/bill/v1"
},
"coupon": { //新增了优惠券抵用的契约
"href": "http://zhaodaisuo.com/orders/123456/coupon"
}
}
}这样版本化的粒度就下移到了服务契约的级别,这时消费者就灵活多了,只要按需修改对应的集成点就行了。
彻底与API的内部实现解耦
不知道在你的开发生涯中有没有遇到过这样的事情:
有一天,产品经理跟我说,我们依赖的一个API发布者通知我,现在判断订单是否能够用优惠券的条件变化,这是他们的联系人。
“你好呀,请问现在订单能否用优惠券的判断条件有什么变化?”
“原来,你们可以通过订单的状态来判断,现在还需要结合订单的来源,参加秒杀活动的订单不能使用优惠券”
“好吧。。。”
于是我在集成代码中做了如下修改:
if (order.status().equals("WAIT_PAYMENT")) {
if (order.source().equals("miaosha")) {
couponButtonEnabled = false;
} else {
//....
}
} else {
//...
}好纠结,就不能把API设计成这样吗?
{
"tracking_id": "123456",
"Hotel": "A ZHAO DAI SUO",
"status": "WAIT_PAYMENT",
"source": "normal",
"_links": {
"coupon": {
"href": "http://zhaodaisuo.com/orders/123456/coupon"
}
}
}{
"tracking_id": "123456",
"Hotel": "A ZHAO DAI SUO",
"status": "WAIT_PAYMENT",
"source": "miaosha",
"_links": {} //秒杀来源的订单不返回含优惠券链接的资源表述。
}这样客户端代码就简单了,依赖于抽象的业务场景,而不是依赖于具体的实现
if (order.containsLink("coupon")) {
couponButtonEnabled = true;
} else {
couponButtonEnabled = false;
}其实你是一位API发布方的开发者?
嗯,Hypermedia很好,但我是API的发布者,这对我有什么好处? 很高兴你能看到这里,其他就不多说了,在这个服务竞争激烈的时代,把消费者们哄开心了,有的是你的好处。
在基于Jenkins实现的部署流水线中共享二进制包
只生成一次二进制包
只生成一次二进制包是部署流水线的一条重要原则,部署流水线的后续步骤会重用之前生成的二进制包。 相比每次从源代码构建二进制包,它节约了时间,更重要的是它促进了“你所测试的二进制包就是将要发布的二进制包”的实践。
现在,使用Jenkins来实现部署流水线非常流行,那么如何用Jenkins来实现共享二进制包呢?
拷贝/共享Workspace?
我所见过最常用的方案,但很遗憾,这个方案并不正确。 这种方案只所以流行可能要“归功”于一款插件:Clone Workspace SCM Plug-in, 这款插件可以打包Workspace,这样二进制包就被保存下来供后续步骤复用。
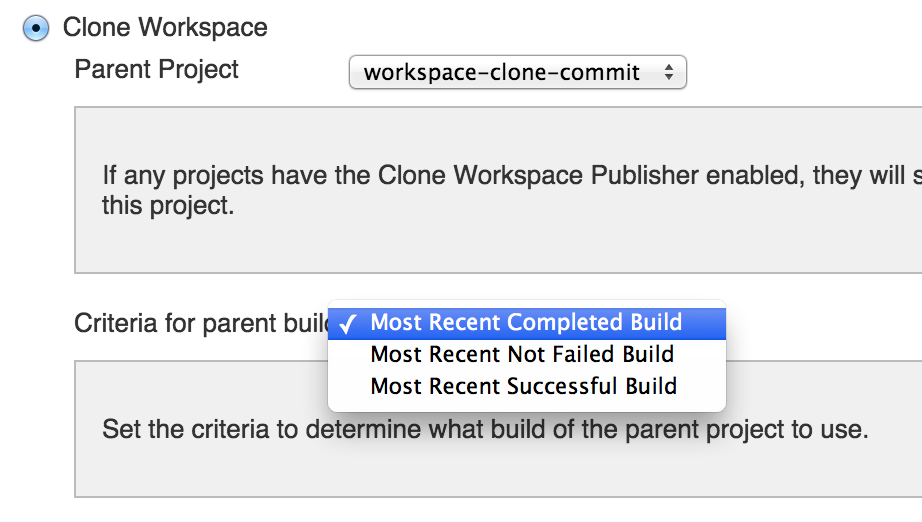
遗憾的是,下游步骤只能选择最新的上游构建的Workspace,这在大部分情况下没有问题, 但并不是每个构建步骤都会触发下游步骤,这种情况多见于进入QA流程的步骤,在部署流水线中, QA不再被动响应二进制包的部署,而是以“拉”模式主动选取要部署的二进制包。 因此,QA并不一定会选取最新的二进制包,但如果使用Clone Workspace SCM Plug-in,这就由不得他们了。

在上图中,如果想要部署workspace-clone-commit#7的二进制包,那么QA会点击红色方框中的build按钮, 但实际上将被部署的是workspace-clone-commit#9生成的二进制包。 这个方案还有一个邪恶的变体:下游步骤指定使用上游步骤的Workspace。
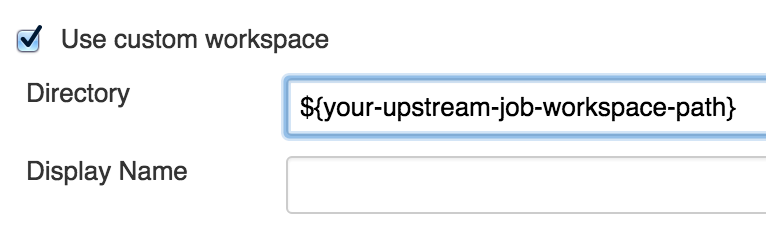
这个问题的可怕之处在于,你可能会将没有做好发布准备的二进制包意外地发布到生产环境中去。
关键是二进制包仓库
拷贝Workspace是不靠谱的,你需要建立二进制包与构建它的部署流水线之间的联系, 这样才能保证取到正确的二进制包。常见的做法是引入二进制包仓库(以下简称制品仓库)。
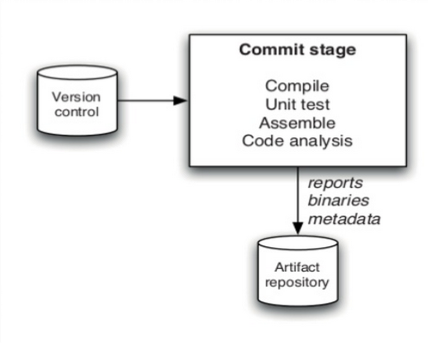
Jenkins自身作为制品仓库
Jenkins自身也可以作为制品仓库,在commit stage的Post-build Actions中加入Archive the artifacts 即可归档Workspace中的指定目录及文件。 接下来需要为后续步建立与二进制包的关联,把该次构建的build number传递下去,这样后续步骤就知道应该去哪拷贝二进制包了。 利用Parameterized Trigger plugin和Build Pipeline Plugin的Manual Trigger 可以分别向自动、手动触发的下游任务传递环境变量,在变量中加入本次构建的build number:
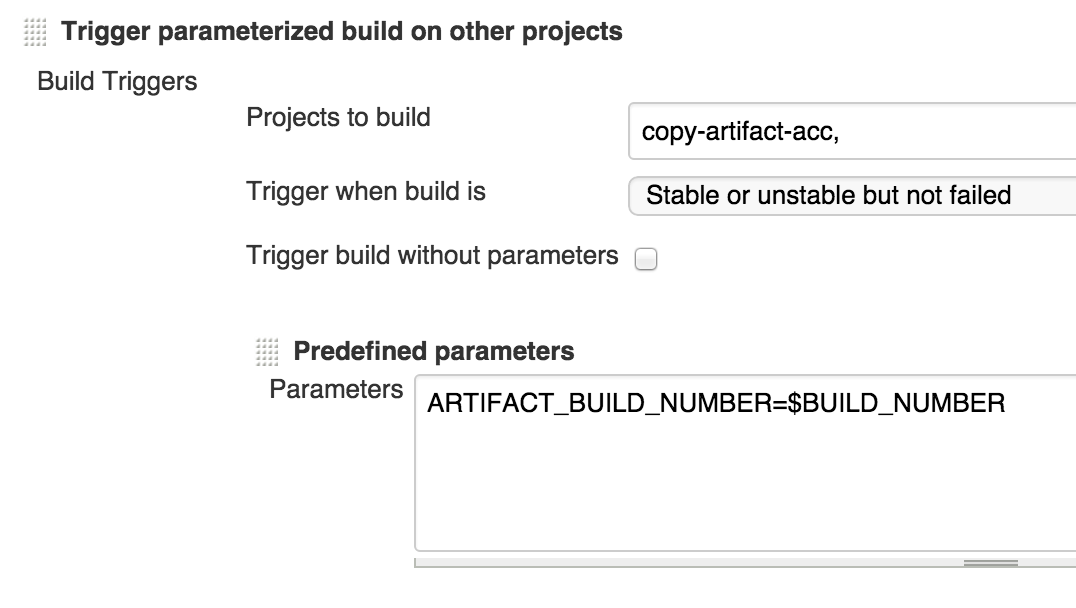
下游步骤利用Copy Artifact Plugin(一定要使用specific build)就可以精确地拷贝二进制包了:
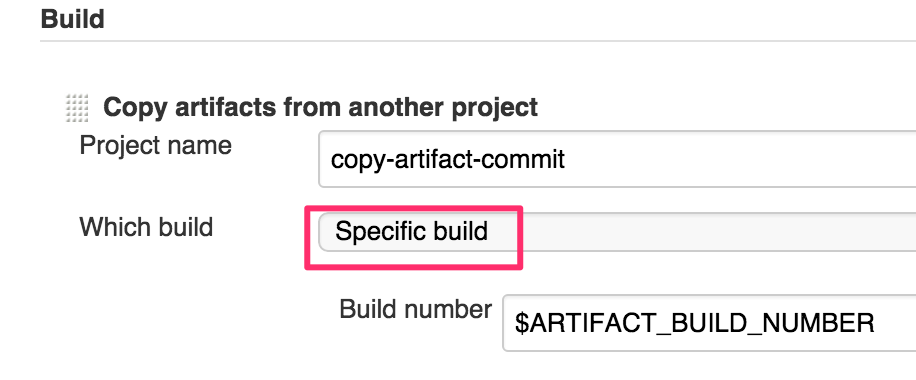
现在,二进制包就可以正确地在部署流水中流转复用了。
利用外部制品仓库
还有一种常见的方案是集成外部仓库,有一些成熟的仓库产品, 比如Nexus。 在构建任务中,将生成的二进制包发布到外部仓库中并通过环境变量将二进制包的信息传递给下游任务。 下游任务按收到的信息下载二进制包即可实现。
大部分外部仓库都提供了REST接口,你可以用过脚本通过http协议来实现下载,也可以考虑让Jenkins的插件Repository Connector Plugin来处理。
在下游任务中,你可以使用Build一节的Artifact Resolver来下载二进制包,它支持环境变量,这样就可以灵活地指定二进制包的版本了。
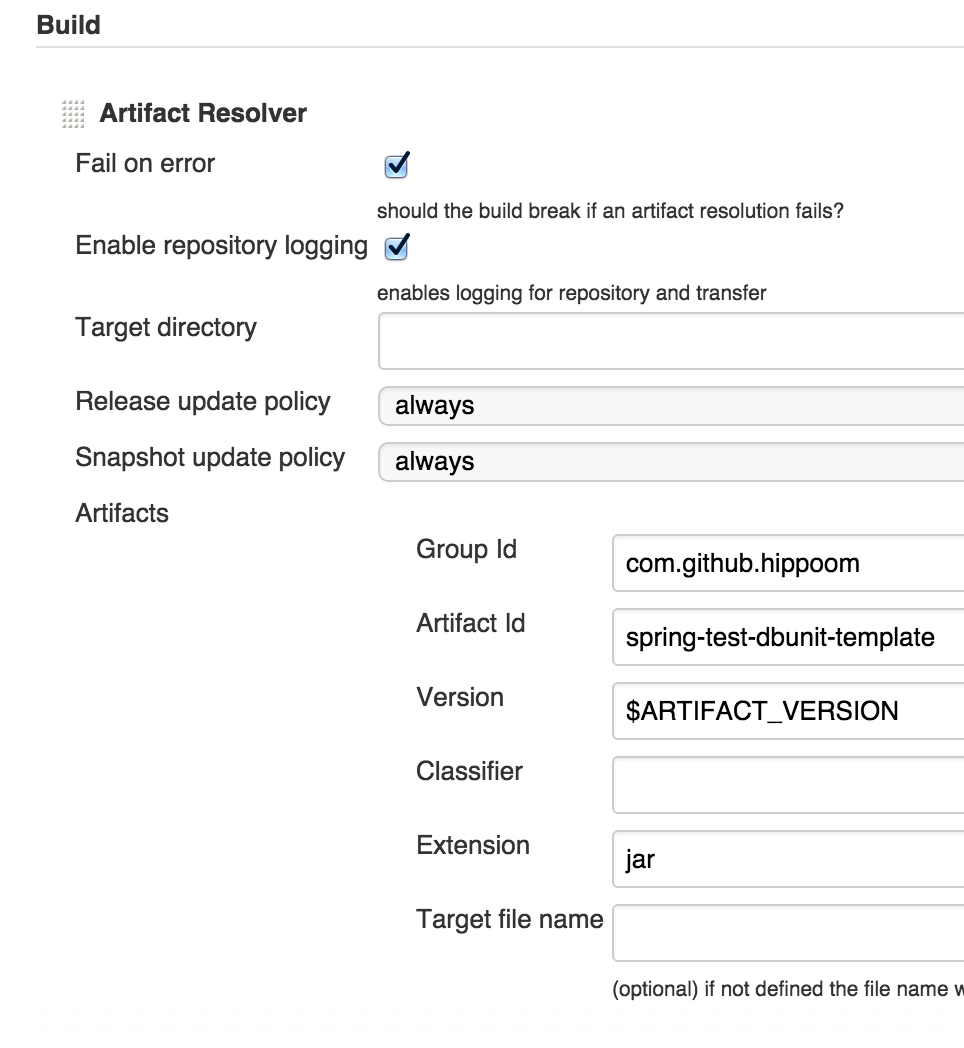
接下来修改构建任务,使用Parameterized Trigger plugin, 它支持将一个properties文件中的key-value转换成环境变量传递给下游任务。 在你的构建脚本中,将二进制包的信息记录到这个properties文件中,这样下游任务就能拿到本次构建生成的二进制包信息了。

总结
在流水线中正确地传递二进制包是非常重要的,但又很容易被忽视。 我们回顾了一些常见的反模式,也介绍了两种常见的解决方案,希望对你有帮助。